前言
虽然Bluetooth SIG专门制订了 《Mesh Model Specification》,但是仍然不能满足目前IOT设备的需求,很多目前市面上现有的产品均没有现成的Model可以拿来直接使用;另外一方面,芯片原厂并没有提供Model标准中指及的全部模型,只提供了部分的模型;但是,蓝牙联盟并没有将路堵死,也给开发者开放了一个Vendor Model,这样让产品的制造商有了更多的余地,这有利于Model的扩展,因为SIG Mesh产品最终还是要过认证的,如果某个厂商自定义的Vendor Model很好,那么蓝牙联盟完全可以采纳;然而,也有另外的一个极端:那就是支持SIG Mesh的不同产品之间的互联互通性就会大打折扣,稍有不慎,很有可能就会走Zigbee当年的老路;但是,小编认为有了Zigbee的前车之鉴,SIG MESH只会越来越好,关于这一点我们在《2020 Bluetooth? Market Update》也能看出来;

好吧,小编承认有点跑题了;再次回到Vendor Model的话题上来😄,那么供应商模型的使用,就会遇到分包重组的问题;至于是自动分包好还是应用层拆包发送好? 小编这里先暂不公布答案,在回答这个问题之前请先看看它们两者之间的区别。
自动分包
何为 “自动分包?”,小编将SIG Mesh协议栈规定的分包方式
,称之为自动分包;不知道读者对下面这幅图还有没有印象:
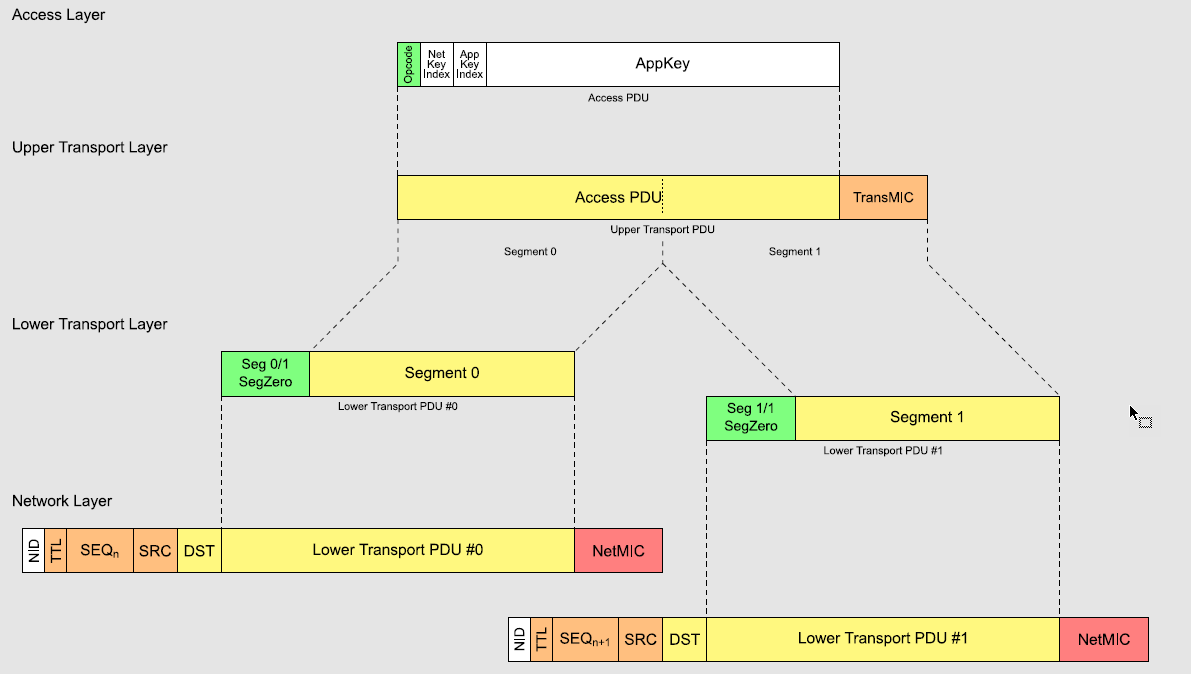
上图就是SIG MESH规范的一个自动分包过程,但是我们要继续讲解这一幅图之前,我们可以先再看看另外一幅图:

根据这两幅图,我们可以得出以下的两个共识:
- 对于Access Message的分包,最长的有效载荷为12Bytes
- Access Message的TransMIC域的内容,只在最后一个分包携带
那么,这个时候我们再回过头来看上述的第一幅图是不是就好理解多了,黄色的Segment0/1就对应的第二幅图的Segmentm(1~12Bytes);既然现在我们已经了解了这个规则,那么小编趁热打铁再抛出一个问题:基于红旭的Vendor Model,小编发送了“Wireless-tech”的字符串信息,那么要分为几包,具体每一包的内容又是什么? 在回答这个问题之前,不知道读者们对Vendor Model浅析的内容还有没有印象,其中小编提及到有效的载荷由Opcode + Parameters + TransMIC三部分组成,其中Opcode + Parameters就是上述第一幅图的Access PDU,Vendor Model的Opcode占用3个字节,所以想要发送 “wireless-tech”,则其具体的分包方式如下图所示:

从上图中,我们可以很清楚地看到当使用红旭Vendor模型,发送 “wireless-tech” 需要分成两包;同时,TransMIC也是在最后一包中被发送出去,基本上每一包明文的数据也均在上面得到体现,我相信读者们此时应该对此过程了然于胸了;

但是,在这里小编不得不提及的是:自动分包这种机制是需要应答的,同时这也是分条件的
- 当目标地址是单播地址时,对端设备是需要发送应答分段消息
- 当目标地址是虚拟地址或者组地址时,对端设备则不用发送应答分段消息
单播地址
不知道读者们对小编之前写的BLE Mesh各层帧包格式详解.分包与重组 还有没有印象,在该章节中小编提及到两个定时器:
- segmentation transmission timer
- acknowledgement timer
为什么在这里要强调这两个定时器? 那是因为发送目标地址为单播地址分包的发送方会使用到segmentation transmission timer,而对端设备则需要使用到acknowledgement timer;对于分包的发送方而言,其发送完第一个分包时开始计时,等待对端设备的应答消息 (最长等待segmentation transmission timer的时长),从而判断对方是否收到其发送的分包数据,如果对端设备接收到全部的分包数据,则停止segmentation transmission timer(还未超时),否则重传所有未应答的消息;而对于分包的接收方而言,当其收到第一包分包时开始计时,等到acknowledgement timer超时,其就将目前收到的消息通过应答消息告诉发送方,如果acknowledgement timer未超时之前,就收到所有的分包PDU,则发送应答消息并停止acknowledgement timer;简单地说就是:
- 发送方必须在segmentation transmission timer时长内收到所有分包被接收到的应答,否则重传未被接收方收到的分包
- 接收方最慢会在acknowledgement timer超时之后,就应答目前为止其接收到的所有分包
更多的详情请参考上述提及的分包与重组章节。
虚拟地址&组地址
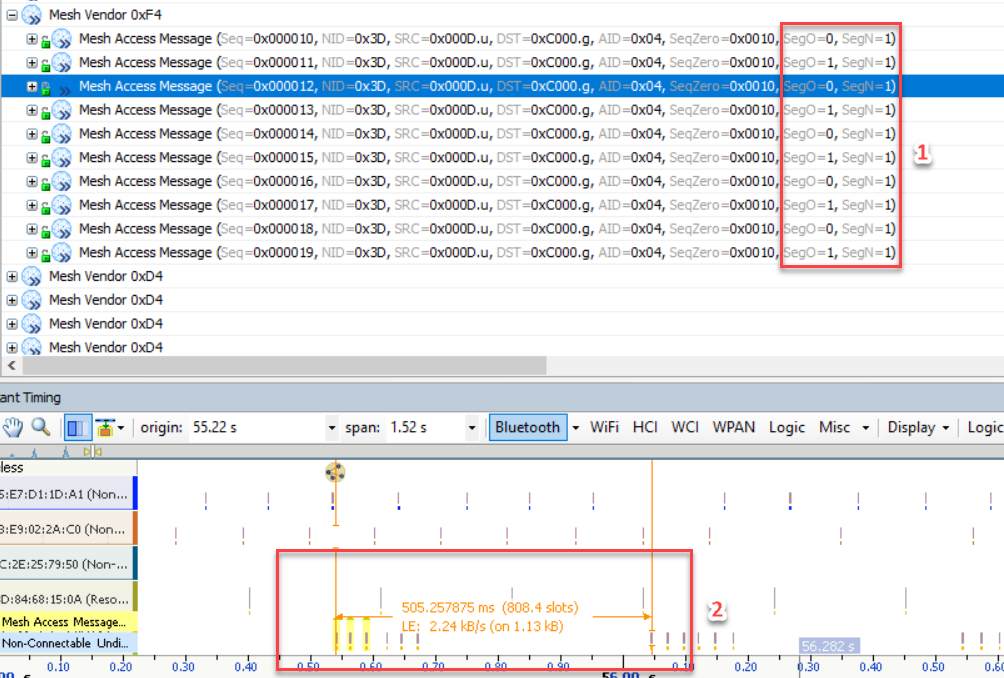
相对于上述的单播地址而言,如果目标地址为虚拟地址或者组地址时,对端设备则不需要发送应答消息;由于SIG Mesh采用的是发布与订阅的对话机制,这也就是说如果目标地址是组地址或者虚拟地址也要应答消息的话,那么整个Mesh网络就会充斥着大量的广播包,从而导致整个网络鲁棒性骤降。针对这种情况,SIG MESH Specification建议多发几次分包,这也就是为什么小编使用红旭Vendor模块发送目标地址为组地址的分包时,发送了4次 (完整的Access PDU发送了4次);
应用层拆包
顾名思义,就是分包的动作交由应用层去处理;我们知道分包与不分包的载荷量是不一样的,既然是应用层分包的话,那么就意味着每一包Network PDU都是不分包的包,只不过应用层将大数据拆分成若干个小数据来发送;(这里的分包与不分包的概念是相对应于自主分包而言) 那么,我们先看看不分包的载荷量有多少?
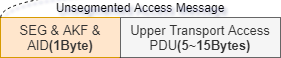
由上图我们可知,不分包且能给应用层用的就是15字节,然后再减去TransMIC,最大能用的就是11个字节,再如果使用的是Vendor模型,那么此时最大能用的就是8个字节了;换句话说:“可以给应用层任意修改的不分包最大载荷量为8个字节(仅限Vendor模型)”,有了这个理论知识之后,我们再看一看应用拆包又是怎么样的?

由上图我们可以很清楚地看出,应用层分包的每一包都携带有Opcode和TransMIC,正因为这样导致应用层拆包时,有效的载荷包没有自动分包多;既然如此,但是应用层分包是不需要应答的 (这里的应答仅仅指的是分包响应,如果采用可靠传输发送这些应用层分包的话,那么每包都会应答;虽然这样做没有问题,但是效率不高,远不如自动分包的机制,所以我们这里不讨论这个),那么这是不是意味着 “自动分包就一定比应用层拆包快呢?”,在回答这个问题之前,我们不妨先做如下两个实验:
- 一次性发送380字节数据,然后统计这两种方式的发送时间
- 每隔100ms,发送20个字节的数据,然后统计这两种方式发送出去的数据包个数,总共发10次
自动分包 VS 应用拆包
至于这两种方式到底谁会胜出?让我们看看应用层拆包章节末尾的实验结果:

实险1
对于实验1所需要测量的时间,其测量的标准如下:

对于自动分包而言,当其把380字节发送出去之后,还需要等待对端设备的分包应答响应,方可认为380字节被发送完成;这也就是说测量的时间为:从开始发送那一刻起,直至分包应答响应被完全收到为止
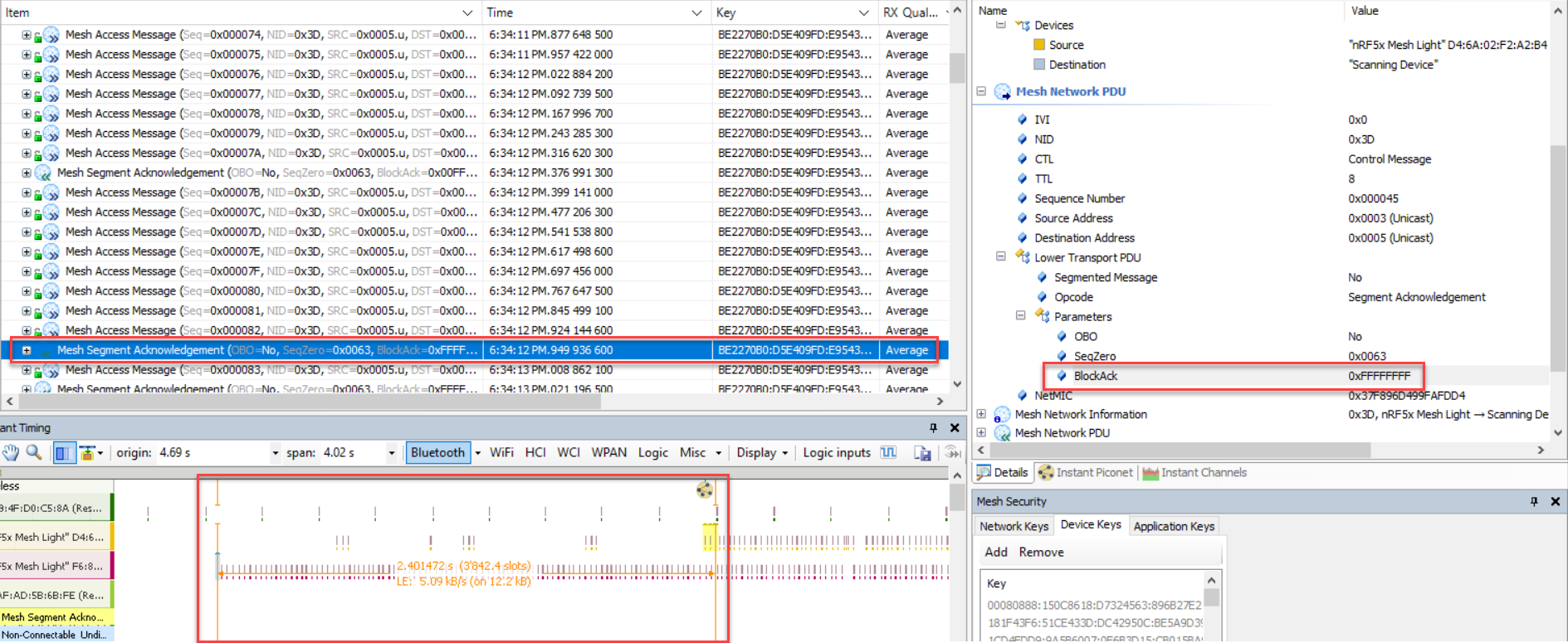
由上图可知,发送380字节共发了32包,用时2.401472s;这里需要注意的是当我们调用以下函数时:
hx_model_client_opcode_tx_unreliable(&m_hx_model_control[1].client_model,test_data,sizeof(test_data)/sizeof(test_data[0])-3,1);这里传进来的长度需要减去3,这是因为传进来的长度指的是想要传输的信息,不包括操作码,而Vendor Model的操作码是3个字节,故要减去3
对于应用拆包的话,其只需要将380字节发送出去即可,那么其测量的时间为:从开始发送那一刻起,直至最后一包被发送完全为止
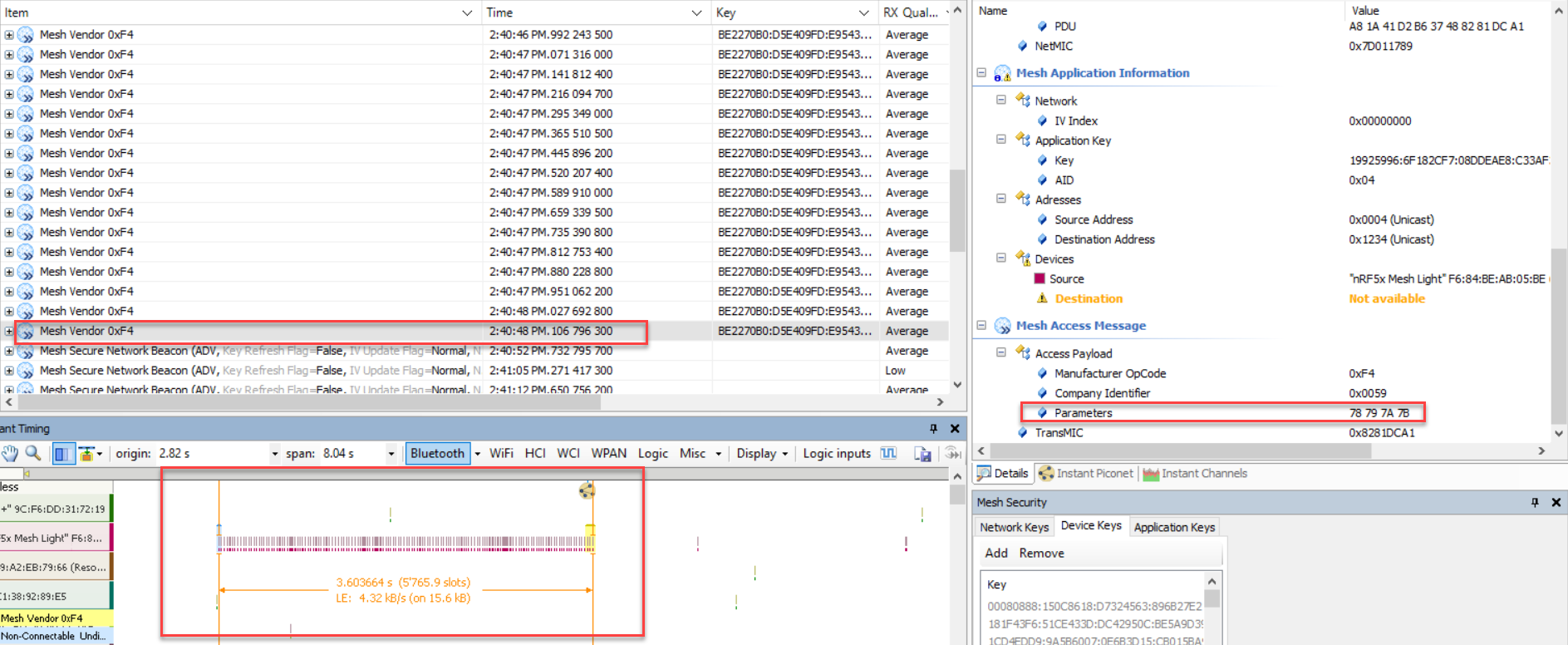
由上图可知,应用层分包共发了48包,用于3.603664s;这里还有一小插曲,当小编在调试应用层分包发送380字节时,发现发送了4次分包之后,一直出现 "NRF_ERROR_NO_MEM" 的问题,起初以为是堆不够,后来小编一层又一层地剥开到7~8层嵌套之后,发现原来是缓存不足 (Nordic SDK的嵌套真特么的深);

只要做如下修改即可实现一次性应用层分包发送380字节:
xxxxxxxxxx/** Core mesh originator queue buffer size */// the default value is 256
从上面的对比实验可知:在同等条件下,一次性传输大数据时还是自动分包会有优势;
实验2
该实验主要用于以一定的时间间隔发送指定长度的数据包,统计对端设备可以收到多少包正确并完整的数据;

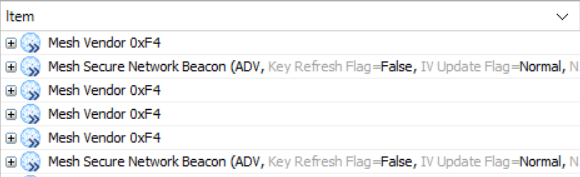
自动分包
当以100ms的时间间隔,发送20字节的数据且发送10次,对端设备只能收到4包20字节的数据
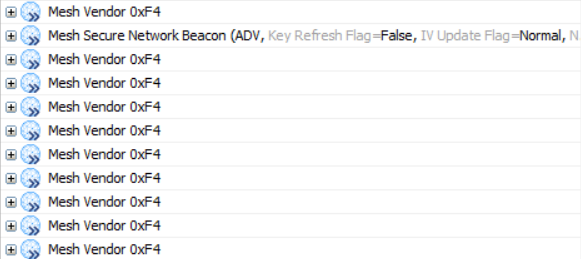
当将时间间隔从100ms变为300ms时,其他的条件不变,对端设备可以收到10包20字节的数据
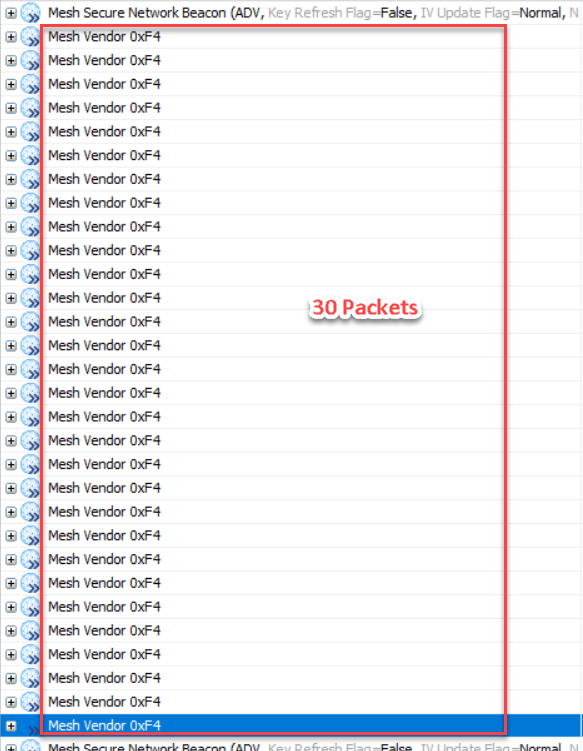
应用层分包
当以100ms的时间间隔,发送20字节的数据且发送10次,对端设备则收到10包20字节的数据
从实验2的实验结果,我们可看出:当以一定间隔发送特定长度的数据时,应用层分包会比自动分包有优势。至于原因,小编在单播地址中已经解释过了;所以,我们不能单方面就认为自主分包与应用层分包孰优孰劣,需要根据具体的条件来判断。